14.23.34.42.50.59.66.72
Do you know what this sequence is?
About the New York city subway and computer science data structures — a blog post on real life city navigation and abstractions for efficient search.
If you live in New York city maybe you guessed it. The sequence represents a trip on the New York city subway (or so I’m told). Stops 14, 23, etc. up until 72.
The New York city subway is a skip list: it works just like the simple efficient dynamic randomised search structure created by William Pugh (1989). When you hop into the NYC subway you may use the express line to jump over stations you know you’re not interested in stopping at.
Going from 14 to 72 you may jump through 23, 50, 59, 66 by taking the express line. Now imagine doing that for linked lists for efficient searching. Instead of traversing the whole list, just jump through some elements on the list, like a pebble ricocheting over water.

The numbered boxes (in yellow) at the bottom represent the ordered data sequence. Searching proceeds downwards from the sparsest subsequence at the top (express lines) until consecutive elements bracketing the search element are found.
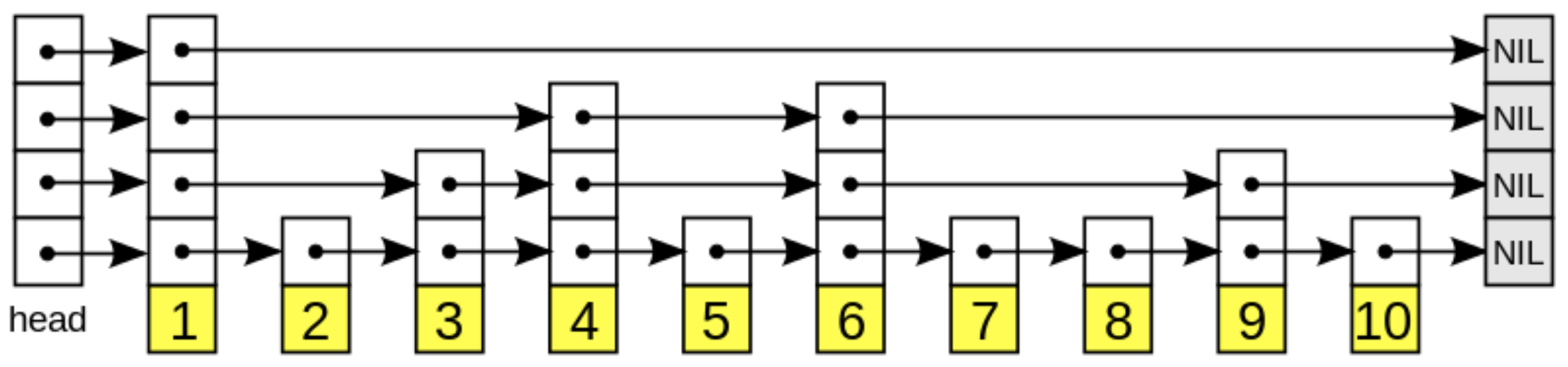
Pugh proved average O(log n) complexity on both insertion and search with skipped elements being picked probabilistically, by means of randomising which nodes get promoted to an upper level, i.e., which nodes are “a part of the [multiple] express lines”.

Compared with other efficient search structures (e.g., treaps, red-black trees, b-trees), the randomized balancing of skip lists has been argued to be easier to implement than the deterministic balancing schemes used in the aforementioned data structures.

Skip lists also prove especially useful in parallel computing, where updates to different parts of the list may be done independently, hence being a great fit for designing highly scalable lock-free efficient search structures.
Lucene, Redis and Google’s LevelDB all use skip lists in their implementation.



Credit for the NYC subway analogy goes to the brilliant Erik Demaine, a professor of computer science at MIT.